


时间:2023-05-30 11:00:01 | 来源:网站运营
时间:2023-05-30 11:00:01 来源:网站运营
【超详细】手把手教你ElasticSearch集群搭建:tar -xvf elasticsearch-7.10.2-linux-x86_64.tar.gz1. groupadd elsearch2. useradd elsearch -g elsearch -p elasticsearch3. chown -R elsearch:elsearch /usr/local/elasticsearch-7.10.2执行以上命令,创建一个名为elsearch用户, 并赋予目录权限。# 外网访问地址network.host: 0.0.0.0systemctl stop firewalld.servicesystemctl disable firewalld.serviceJAVA_HOME=/usr/local/jdk-11.0.11# now set the path to javaif [ ! -z "$JAVA_HOME" ]; then JAVA="$JAVA_HOME/bin/java"else if [ "$(uname -s)" = "Darwin" ]; then # OSX has a different structure JAVA="$ES_HOME/jdk/Contents/Home/bin/java" else JAVA="$ES_HOME/jdk/bin/java" fifi* soft nofile 65536* hard nofile 131072* soft nproc 2048* hard nproc 4096elsearch soft nproc 125535elsearch hard nproc 125535重新切换用户即可:tar -xvf kibana-7.10.2-linux-x86_64.tar.gzchown -R elsearch:elsearch kibana-7.10.2-linux-x86_64# 服务端口server.port: 5601# 服务地址server.host: "0.0.0.0"# elasticsearch服务地址elasticsearch.hosts: ["http://192.168.116.140:9200"]./kibana -q看到以下日志, 代表启动正常log [01:40:00.143] [info][listening] Server running at http://0.0.0.0:5601如果出现启动失败的情况, 要检查集群各节点的日志, 确保服务正常运行状态。PUT orders{ "settings": { "index": { "number_of_shards": 2, "number_of_replicas": 2 } }}查看索引信息, 会出现yellow提示:PUT orders{ "settings": { "index": { "number_of_shards": 2, "number_of_replicas": 0 } }}将分片数设为0, 再次查看, 则显示正常:## 创建索引PUT orders3.2 查询索引orders## 查询索引GET orders "number_of_shards" : "1", ## 主分片数 "number_of_replicas" : "1", ## 副分片数 3.3 删除索引 ## 删除索引 DELETE orders 3.4 索引的设置 ## 设置索引 PUT orders { "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0 } } }## 创建文档,生成默认的文档idPOST orders/_doc{ "name": "袜子1双", "price": "200", "count": 1, "address": "杭州市"}## 创建文档,生成自定义文档idPOST orders/_doc/1{ "name": "袜子1双", "price": "2", "count": 1, "address": "杭州市"}4.2 查询文档## 根据指定的id查询GET orders/_doc/1## 根据指定条件查询文档GET orders/_search{ "query": { "match": { "address": "杭州市" } }}## 查询全部文档GET orders/_search4.3 更新文档## 更新文档POST orders/_doc/1{ "price": "200"}## 更新文档POST orders/_update/1{ "doc": { "price": "200" }}4.4 删除文档## 删除文档DELETE orders/_doc/1## 设置mapping信息PUT orders/_mappings{ "properties":{ "price": { "type": "long" } }}## 设置分片和映射PUT orders{ "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0 } }, "mappings": { "properties": { "name": { "type": "text" }, "price": { "type": "long" }, "count": { "type": "long" }, "address": { "type": "text" } } }}PUT my_date_index/_doc/1{ "date": "2021-01-01" } PUT my_date_index/_doc/2{ "date": "2021-01-01T12:10:30Z" } PUT my_date_index/_doc/3{ "date": 1520071600001 } 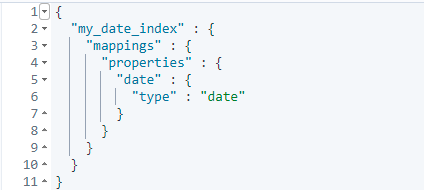 ES的Date类型允许可以使用的格式有: > yyyy-MM-dd HH:mm:ss > yyyy-MM-dd > epoch_millis(毫秒值)3. 复合类型 复杂类型主要有三种: Array、object、nested。 + Array类型: 在Elasticsearch中,数组不需要声明专用的字段数据类型。但是,在数组中的所有值都必须具有相同的数据类型。举例: ```sh POST orders/_doc/1 { "goodsName":["足球","篮球","兵乓球", 3] } POST orders/_doc/1 { "goodsName":["足球","篮球","兵乓球"] } ``` + object类型: 用于存储单个JSON对象, 类似于JAVA中的对象类型, 可以有多个值, 比如LIST<object>,可以包含多个对象。 但是LIST<object>只能作为整体, 不能独立的索引查询。举例: ```sh # 新增第一组数据, 组别为美国,两个人。 POST my_index/_doc/1 { "group" : "america", "users" : [ { "name" : "John", "age" : "22" }, { "name" : "Alice", "age" : "21" } ] } # 新增第二组数据, 组别为英国, 两个人。 POST my_index/_doc/2 { "group" : "england", "users" : [ { "name" : "lucy", "age" : "21" }, { "name" : "John", "age" : "32" } ] } ``` 这两组数据都包含了name为John,age为21的数据, 采用这个搜索条件, 实际结果: ```sh GET my_index/_search { "query": { "bool": { "must": [ { "match": { "users.name": "John" } }, { "match": { "users.age": "21" } } ] } } } ``` 结果可以看到, 这两组数据都能找出,因为每一组数据都是作为一个整体进行搜索匹配, 而非具体某一条数据。 + Nested类型 用于存储多个JSON对象组成的数组,`nested` 类型是 `object` 类型中的一个特例,可以让对象数组独立索引和查询。 举例: 创建nested类型的索引: ```sh PUT my_index { "mappings": { "properties": { "users": { "type": "nested" } } } } ``` 发出查询请求: ```sh GET my_index/_search { "query": { "bool": { "must": [ { "nested": { "path": "users", "query": { "bool": { "must": [ { "match": { "users.name": "John" } }, { "match": { "users.age": "21" } } ] } } } } ] } } } ``` 采用以前的条件, 这个时候查不到任何结果, 将年龄改成22, 就可以找出对应的数据: ```sh "hits" : [ { "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_score" : 1.89712, "_source" : { "group" : "america", "users" : [ { "name" : "John", "age" : "22" }, { "name" : "Alice", "age" : "21" } ] } } ] ``` 4. GEO地理位置类型 现在大部分APP都有基于位置搜索的功能, 比如交友、购物应用等。这些功能是基于GEO搜索实现的。 对于GEO地理位置类型,分为地理坐标类型:Geo-point, 和形状:Geo-shape 两种类型。 | 经纬度 | 英文 | 简写 | 正数 | 负数 | | :----- | :-------- | :------- | :--- | ---- | | 维度 | latitude | lat | 北纬 | 南纬 | | 经度 | longitude | lon或lng | 东经 | 西经 | 创建地理位置索引: ```sh PUT my_locations { "mappings": { "properties": { "location": { "type": "geo_point" } } } } ``` 添加地理位置数据: ```sh # 采用object对象类型 PUT my_locations/_doc/1 { "user": "张三", "text": "Geo-point as an object", "location": { "lat": 41.12, "lon": -71.34 } } # 采用string类型 PUT my_locations/_doc/2 { "user": "李四", "text": "Geo-point as a string", "location": "45.12,-75.34" } # 采用geohash类型(geohash算法可以将多维数据映射为一串字符) PUT my_locations/_doc/3 { "user": "王二麻子", "text": "Geo-point as a geohash", "location": "drm3btev3e86" } # 采用array数组类型 PUT my_locations/_doc/4 { "user": "木头老七", "text": "Geo-point as an array", "location": [ -80.34, 51.12 ] } ``` 需求:搜索出距离我{"lat" : 40,"lon" : -70} 200km范围内的人: ```sh GET my_locations/_search { "query": { "bool": { "must": { "match_all": {} }, "filter": { "geo_distance": { "distance": "200km", "location": { "lat": 40, "lon": -70 } } } } } } ```## 2. ES高可用集群配置### 2.1 ElasticSearch集群介绍+ **主节点(或候选主节点)** 主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作, 主节点负荷相对较轻, 客户端请求可以直接发往任何节点, 由对应节点负责分发和返回处理结果。 一个节点启动之后, 采用 Zen Discovery机制去寻找集群中的其他节点, 并与之建立连接, 集群会从候选主节点中选举出一个主节点, 并且一个集群只能选举一个主节点, 在某些情况下, 由于网络通信丢包等问题, 一个集群可能会出现多个主节点, 称为“脑裂现象”, 脑裂会存在丢失数据的可能, 因为主节点拥有最高权限, 它决定了什么时候可以创建索引, 分片如何移动等, 如果存在多个主节点, 就会产生冲突, 容易产生数据丢失。要尽量避免这个问题, 可以通过 discovery.zen.minimum_master_nodes 来设置最少可工作的候选主节点个数。 建议设置为(候选主节点/2) + 1 比如三个候选主节点,该配置项为 (3/2)+1 ,来保证集群中有半数以上的候选主节点, 没有足够的master候选节点, 就不会进行master节点选举,减少脑裂的可能。 主节点的参数设置: ```sh node.master = true node.data = falsenode.master = falsenode.data = truenode.master = falsenode.data = falsenode.ingest = truePUT orders{ "settings":{ "number_of_shards":2, ## 主分片 2 "number_of_replicas":2 ## 副分片 4 }}mkdir /usr/local/clustercd /usr/local/clustertar -xvf elasticsearch-7.10.2-linux-x86_64.tar.gz将安装包解压至/usr/local/cluster目录。vi /usr/local/cluster/elasticsearch-7.10.2-node1/config/elasticsearch.yml 192.168.116.140, 第一台节点配置内容:# 集群名称cluster.name: my-application#节点名称node.name: node-1# 绑定IP地址network.host: 192.168.116.140# 指定服务访问端口http.port: 9200# 指定API端户端调用端口transport.tcp.port: 9300#集群通讯地址discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]#集群初始化能够参选的节点信息cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]#开启跨域访问支持,默认为falsehttp.cors.enabled: true##跨域访问允许的域名, 允许所有域名http.cors.allow-origin: "*"修改目录权限:chown -R elsearch:elsearch /usr/local/cluster/elasticsearch-7.10.2-node1cd /usr/local/clustercp -r elasticsearch-7.10.2-node1 elasticsearch-7.10.2-node2cp -r elasticsearch-7.10.2-node1 elasticsearch-7.10.2-node3# 集群名称cluster.name: my-application#节点名称node.name: node-2# 绑定IP地址network.host: 192.168.116.140# 指定服务访问端口http.port: 9201# 指定API端户端调用端口transport.tcp.port: 9301#集群通讯地址discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]#集群初始化能够参选的节点信息cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]#开启跨域访问支持,默认为falsehttp.cors.enabled: true##跨域访问允许的域名, 允许所有域名http.cors.allow-origin: "*"192.168.116.140 第三台节点配置内容:# 集群名称cluster.name: my-application#节点名称node.name: node-3# 绑定IP地址network.host: 192.168.116.140# 指定服务访问端口http.port: 9202# 指定API端户端调用端口transport.tcp.port: 9302#集群通讯地址discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]#集群初始化能够参选的节点信息cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]#开启跨域访问支持,默认为falsehttp.cors.enabled: true##跨域访问允许的域名, 允许所有域名http.cors.allow-origin: "*"su elsearch/usr/local/cluster/elasticsearch-7.10.2-node1/bin/elasticsearch -d/usr/local/cluster/elasticsearch-7.10.2-node2/bin/elasticsearch -d/usr/local/cluster/elasticsearch-7.10.2-node3/bin/elasticsearch -d注意: 如果启动出现错误, 将各节点的data目录清空, 再重启服务。elasticsearch.hosts: ["http://192.168.116.140:9200","http://192.168.116.140:9201","http://192.168.116.140:9202"]重启kibana服务, 进入控制台:PUT orders{ "settings": { "index": { "number_of_shards": 2, "number_of_replicas": 2 } }}可以看到, 这次结果是正常:PUT orders{ "settings": { "index": { "number_of_shards": 2, "number_of_replicas": 5 } }}可以看到出现了yellow警告错误:本文由传智教育博学谷 - 狂野架构师教研团队发布如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力转载请注明出处!
关键词:详细,把手


 在线咨询
在线咨询
